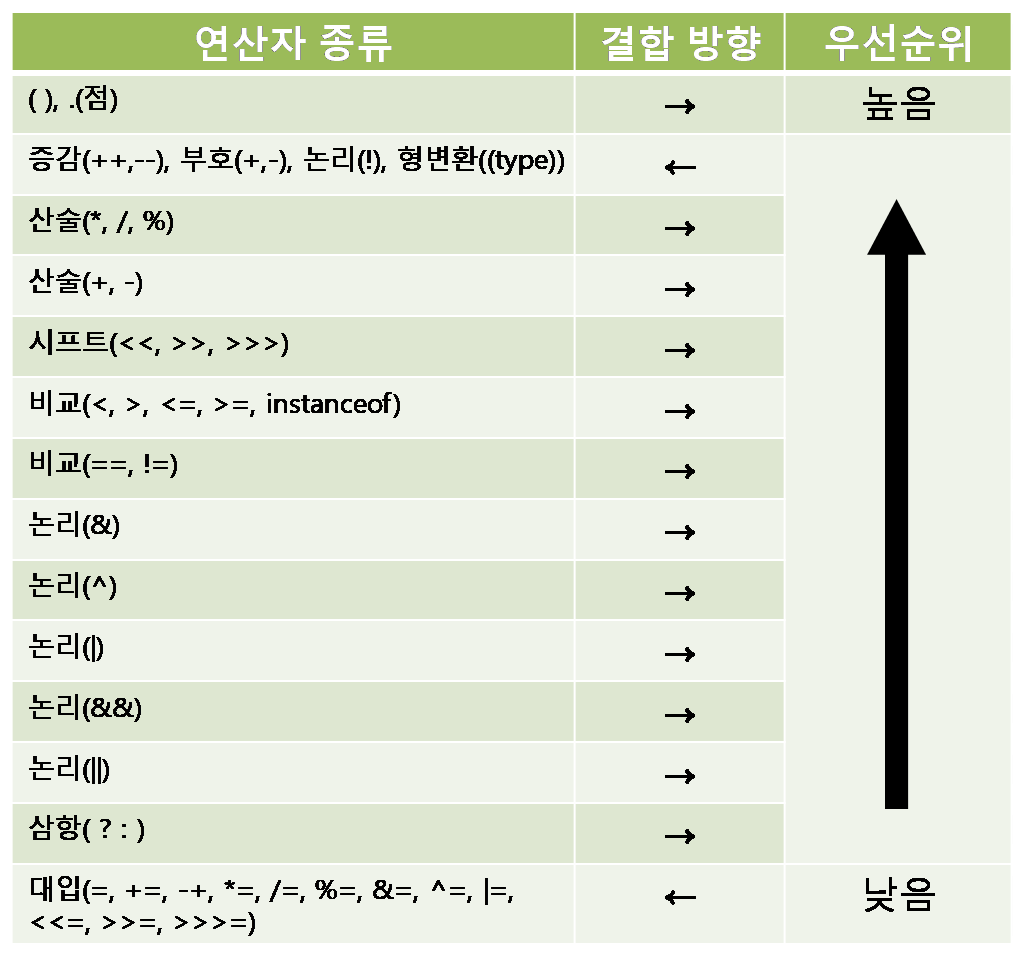
연산자 우선 순위
산술 연산자

boolean type을 제외한 모든 기본형 데이터에서 사용가능하다.
산술연산시 형변환
연산하기 전에 피연산자의 형(타입)을 먼저 일치시킨 후 연산을 진행한다.
1. 피연산자의 크기가 int(4byte)미만인 경우 모두 int로 자동 형변환 후 연산한다.
byte b1=10;
byte b2=20;
byte b3=b1+b2; //Type mismatch : cannot convert from int to byte이클립스에 작성해보면 오류메세지가 발생하는 것을 확인할 수 있다.
그 이유는 byte 타입의 변수를 각각 int로 변경되는 연산이 먼저 진행되고, 그 후 두 int를 더하기 때문에 결과는 int가 나오게 된다. 따라서 이때는 명시적 변환이 필요하다.
byte+byte=(int)byte+(int)byte=int
2. int이상의 타입이 피연산자로 있을때 두개의 피연산자 중 큰 타입으로 묵시적 형변환이 이루어진 후 연산한다.
int i1=100;
long l1=200;
int i2=i1+l1; //type mismatchint+long=(long)int+long=long
변수의 연산과 리터럴 연산의 차이
- int이하의 리터럴 간의 연산은 별도의 형변환이 일어나지 않는다.
- 리터럴 간의 연산은 컴파일러가 컴파일하기 전에 리터럴간의 연산을 수행한 이후에 할당한다.
정수연산의 문제점-오버플로우(overflow)
- 정수들은 최대 값과 최소 값이 띠처럼 맞닿아 있는 구조이다.
따라서 최대값에 1을 더하면 최소값이 된다. - 오버플로우는 연산하는 과정에서 발생하기 때문에 연산 전에 미리 더 큰 데이터 타입을 준비해야한다.

int i1=Integer.MAX_VALUE;
//int의 최대값과 1을 더하므로 오버플로우 발생
int i2=i1+1;
System.out.println("정수 overflow:"+i2); //-21474863648
//더하기 과정에서 오버플로우가 발생했으므로 쓰레기 값이 long이라는 큰 공간을 할당 받음
long l1=i1+1;
System.out.println("long 타입에 할당:"+l1); //-21474863648
//더하기 결과를 형변환 후 long타입의 변수에 할당.
//형환전에 +연산을 먼저 수행하므로 쓰레기값이 할당됨
long l2=(long)(i1+1);
ystem.out.println("캐스팅 된 값:"+l2) //-21474863648
//연산전에 i1을 먼저 형변환. 연산시 큰 타입으로 형변환 후 연산을 진행하므로
//long+long의 형태가 되고 결과는 역시 long이다. 따라서 정상적인 연산가능
long l3=(long)i1+1; //21474863648
//*, / 연산자는 우선순위가 동일하고 결합 방향은 오른쪽이다.
int i3=1_000_000*1_000_000/100_000; //-7273
int i4=1_000_000/1_000_000*100_000; //1,000,000
실수형의 문제점은 정확도
float f1=2.0f;
float f2=1.1f;
float f3=f1-f2;
double d1=2.0;
double d2=1.1;
double d3=d1-d2;
System.out.println("결과비교:"+(f3==d3+", f3"+f3+", d3:"+d3);
//결과비교:false, f3:0.9, d3:0.899999999999
2.0-1.1 연산을하면 누가 봐도 답은 0.9이다. 하지만 컴퓨터는 그렇게 생각하지 못 한다.
즉, 실수형은 연산의 결과가 부정확하다.
실수형 끼리의 연산을 정확하게 하기 위해서는
1. 실수를 정수로 변경해서 처리하는 방법
2. BigDecimal과 같은 미리 제공된 API를 사용하는 방법
이 있다.
//1. 실수를 정수로 변경해서 처리하는 방법
int i1=(int)(d1*10);
int i2=(int)(d2*10);
double result=(i1-i2)/10.0; //0.9
//2. BigDecimal과 같은 미리 제공된 API를 사용하는 방법
BigDecimal bd1=new BigDecimal("2.0");
BigDecimal bd2=new BigDecimal("1.1");
System.out.println(bd1,subtract(bd2));
infinity와 NaN
오른쪽의 피연산자가 0이 되는 경우, / 와 % 연산을 할때 주의해야한다.
이 경우, 정수를 0으롤 나눌때와 실수를 0으로 나눌때 다르게 동작한다.
1. 정수를 이용한 연산
int i=1/0; //ArithmeticException 발생
int i=1%0; //ArithmeticException 발생정수형에서 0으로 연산을 하면 ArithmeticException가 발생한다.
이런 경우 try~catch라는 예외 처리 구문을 이용해서 명확히 오류에 대한 대처 구문을 작성할 수 있다
try{
int i=1/0;
//ArithmeticException 발생
}catch (ArithmeticException e){
System.out.println("예외 처리 완료: 0으로 나눌 수 없습니다.");
}
2. 실수를 이용한 연산
double d1=1/0.0; //infinity
double d2=1%0.0; //NaN실수형에서 0으로 나누면 몫은 infinity가 나오고 나머지는 nan이 나온다. (그러나 이러한 연산의 결과가 오류는 아니다. )
이 두가지는 어떤 것과 연산을 해도 infinit와 nan 값이나온다.
이와 같은 상황을 대비하기 위해서 Double 클래스가 제공하는 isInfinite와 IsNaN 매서드를 이용해 값의 상태를 확이하는 방법이 제공된다.

대입 연산자

복합 대입연산자는 산술연산자, 논리연산자, 시프트 연산자와 결합이 가능하다.
int i1=10;
i1+=20; //i1=30
i1-=10; //i1=20
i1*=10; //i1=200
i1/=10; //i1=20
i1%=2; //i1=0
비교 연산자

-
주로 if 제어문, 반복문에서 실행 흐름 제어에 사용된다.
-
대소 비교 연산자(<,>,<=,>=)는 boolean타입을 제외한 기본형에만 사용할 수 있다.
-
blooean 타입이나 참조형 데이터 타입은 비교연산자중 ==과 !=만 사용할 수 있다.
참조형 변수에서 사용되는 ==은 내용을 비교하는 것이 아니라 두개의 참조형 변수가 정확히 같은 객체를 잠조하는지를 비교한다.
(객체의 내용을 비교하기 위해서는 equals 메서드를 재저으이 해서 사용한다.) -
비교하는 데이터 타입에 따라 동작 방식이 약간씩 다르다.
char는 유니코드로 변경 후 비교한다.
System.out.println('A'>'B'); //false
System.out.println('A'==65); //true'A'는 65, 'B'는 66에 매핑되는 문자이다. 따라서 출력결과는 위처럼 나온다.
정수형 자료 비교시,
int이하의 자료들을 비교할 때 먼저 int로 자료형을 맞추거나 두개의 피연산자 중 큰 데이터 타입으로 형변환을 한다.
System.out.println(3==3.0); //true3은 int타입의 자료이고, 3.0은 double타입의 자료형이다.
double이 큰 타입이므로 앞의 int인 3을 double로 변환 후 연산한다. 따라서 둘은 같다.
실수형 자료 비교시,
System.out.println(0.1+","+0.1f+","+(0.1==0.1f)); //0.1,0.1,falsedouble타입의 0.1과 float타입의 0.1을 출력했을때는 둘 다 모두 0.1로 출력된다.
그러나 동등비교를 해보면 float타입의 0.1이 double로 변환되는 과정에서 근사값으로 표현되기때문이다.
따라서 실수를 비교할때는 정수로 변경해서 비교하거나, 형변환을해서 연산하는 것이 좋다.
double d1=0.1;
float f1=0.1f;
System.out.println((int)(d1*10)==(int)(f1*10));
System.out.println((float)d1==f1);
논리 연산자
논리연산자

예시
boolean b1=true;
boolean b2=false;
boolean b3=false;
System.out.println(b1&b2); //false
System.out.println(b1|b2); //true
System.out.println(b1^b2); //true
System.out.println(b2^b3); //false
System.out.println(!b1); //false
숏 서킷(Short Circuit) 연산자
불필요한 연산을 줄여서 프로그램의 성능을 좋게 한다.(복합 비교시 주로 사용)

예시
int a=10;
int b=20;
System.out.println((a+=10)>15|(b-=10)>15); //true
System.out.println("a="+a+", b="+b); //a=20, b=10
//변수 a,b초기화
a=10;
b=20;
System.out.println((a+=10)>15||(b-=10)>15); //true
System.out.println("a="+a+", b="+b); //a=20, b=20(a+=10)>15의 연산결과가 true이므로 || 연산자이 오른쪽 부분은 연산을 진행하지 않는다.
증감 연산자

int num=0;
num++; //1
num++; //2
num++; //3
int num2=0;
num2--; //-1
num2--; //-2
num2--; //-3위의 예시를 디버깅 해보면 ++연산자는 1씩 증가되고 --연산자는 -1씩 감소되는 것을 확인할 수 있다.
그런데, 증감연산자가 변수의 앞,뒤 중 어느곳에 있는지에 따라 값이 다르게 출력되므로 주의가 필요하다.
증감 연산자의 위치
1. 전위연산자
++a, --a
연산자가 변수 앞에 있으면 연산의 우선순위가 대입연산자보다 빠르다.
변수의 값을 증감해서 메모리에 있는 값을 변경 시킨후 다음 동작(출력, 대입 등)을 진행한다.
2, 후위연산자
a++, a--
연산자가 변수 뒤에 있으면 연산의 우선 순위가 대입연산자보다 느리다.
먼저 출력, 대입 등을 처리한 후에 변수의 값을 증감시킨다.
int num3=0;
// ++ 연산자가 변수 뒤에 있으면 연산의 우선 순위가 대입연산자(=)보다 느리다.
//result1 에는 0이 대입된다.
int result1 = num3++; // 대입을 하고나서 연산한다.
int num4=0;
// ++ 연산자가 변수 앞에 있으면 연산의 우선순위가 대입연산자(=)보다 빠르다.
//result2에는 1이 대입된다.
int result2 = ++num4; // 연산을 하고 나서 대입한다.
증감연산자의 형변환
산술연산자 부분에서 말했듯이 정수연산의 최소 단위는 int이며, int보다 작은 크기의 자료를 연산하면 묵시적으로 int로 형변환 후 연산을 진행한다.
하지만, 증감연산자나 복합대입 연산자의 경우, 타입에 대한 변화가 발생하지 않는다.
byte b1=10;
b1+=1; //형변환 일어나지 않음
System.out.println(b1);
byte b2=++b1; //형변환 일어나지 않음
System.out.println(b2);
byte b3=(byte)(b2+1); //산술연산시 int로 형변환이 일어남
System.out.println(b3);마지막 b3변수에 담기전 산술연산을 하면서 int로 자료형 변환이 일어남으로 byte타입의 변수에 값을 할당해주기 위해서는 casting을 해주어야한다.
3항 연산자

'JAVA' 카테고리의 다른 글
| 클래스(class)와 객체(object, instance) (0) | 2019.12.01 |
|---|---|
| 변수 (0) | 2019.11.30 |
| 이클립스 export / import / delete 하는 방법 (0) | 2019.11.29 |
| JAVA 테이터형의 종류 / casting (0) | 2019.11.28 |
| Object 객체와 Method 사용법 Field 영역 접근 (0) | 2019.11.28 |
